

Por Artur L. Di Fante
1. Introdução
1.1 Contexto
Em média o brasileiro se muda cerca de seis vezes na vida. Quase todas as pessoas passaram por um período de busca por uma nova casa. Existem muitas opções e fontes diferentes para pesquisar, é quase impossível para nós olharmos uma por uma. Sabendo disso, como podemos usar a ciência de dados para nos ajudar a encontrar nosso novo lar?
1.2 Problema
Recebemos uma oferta de trabalho em São Paulo. Como esta oferta é para um endereço específico, selecionamos alguns bairros próximos para morar. Embora tenhamos selecionado estes bairros, ainda há muitos apartamentos para alugar. Temos algumas exigências em relação aos locais próximos, que serão levadas em consideração na escolha da nossa moradia.
Com base na definição do nosso problema, os fatores que influenciarão nossa decisão são:
- O apartamento deve ter pelo menos 2 quartos
- O valor mensal do aluguel não pode ultrapassar R$ 1.700,00
- Deve estar pelo menos 5 km do local de trabalho
- Deve estar perto de pelo menos 1 km de uma academia e um mercado
- Características sociais e econômicas do bairro com base nos dados disponíveis
Usaremos nossas técnicas de ciência de dados para gerar os apartamentos mais promissores para morarmos. Dados econômicos e características sociais dos bairros serão considerados no processo.
1.3 Interesse
Este projeto é direcionado a todos que possam ter interesse em saber mais sobre preços de aluguel de apartamentos, estatísticas dos bairros ou apenas que desejam se mudar para São Paulo, Brasil.
2. Dados
2.1 Fontes de dados
As seguintes fontes de dados serão necessárias para extrair / gerar as informações necessárias:
- A coordenada do local de trabalho será obtida usando o geocoder
- Dados econômicos e de localização de propriedades alugadas no local de trabalho serão obtidos por meio de webscraping de um grande portal online
- Locais próximos em torno de cada bairro serão obtidos usando a API do Foursquare
Dos dados de nossas propriedades, podemos extrair:
- Tipologia
- Bairro
- Valor do aluguel
- Valor de condomínio
- Valor de IPTU
- Quartos
- Suítes
- Banheiros
- Vagas de estacionamento
- Área privada
- Mobiliado
- Comodidades
- Latitude
- Longitude
Da API do Foursquare, podemos extrair:
- Bairros
- Latitude dos bairros
- Longitude dos bairros
- Local
- Nome do local, por exemplo, o nome de uma loja ou restaurante
- Latitude do local
- Longitude do local
- Categoria de local
2.2 Limpezas de Dados
Como nossos dados de aluguel foram obtidos por meio de um portal online, os valores foram filtrados antecipadamente para bairros próximos ao nosso ponto de partida. Havia muitos valores ausentes, especialmente dados de localização. Todas as propriedades que não tinham o endereço completo com rua, número e bairro foram retirados do conjunto de dados. Algumas propriedades tinham o endereço, mas não tinham a latitude e longitude preenchidas, para corrigir isso usamos a biblioteca geooder para preencher esses campos. Outros campos que estavam faltando, como valor do aluguel, área, imposto sobre a propriedade, etc., não foram descartados.
Em nossos dados de bairros e locais, os dados só precisaram ser agrupados.
3. Metodologia
3.1 Filtrando a distância ao local de trabalho
O primeiro filtro foi feito com o objetivo de conseguirmos apenas apartamentos em um raio de 5 km para o nosso local de trabalho. Não foram filtrados muitos imóveis (~ 0,33%) e isso porque já havíamos filtrado os bairros para apurar os dados.
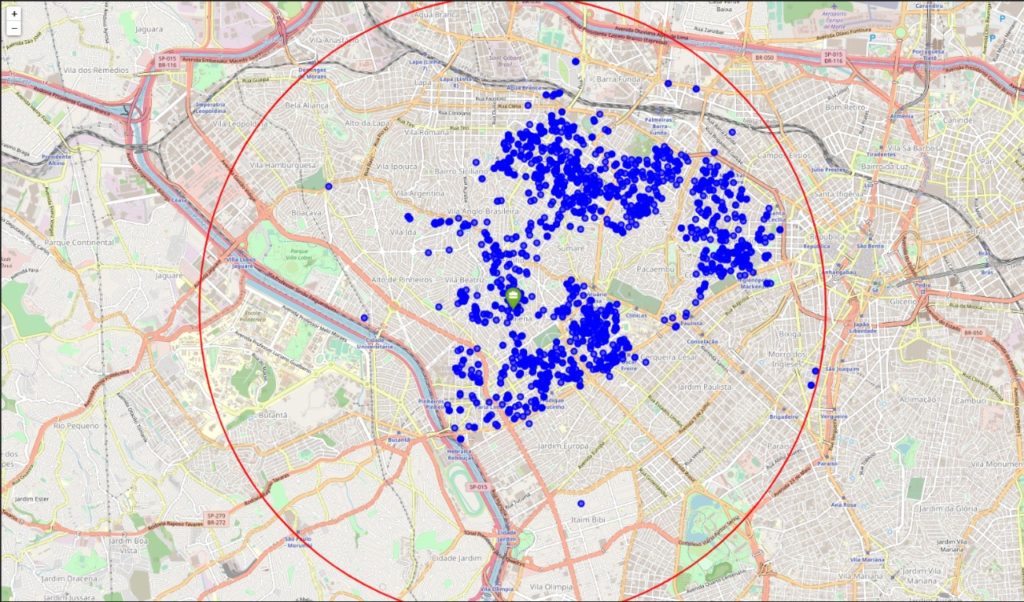
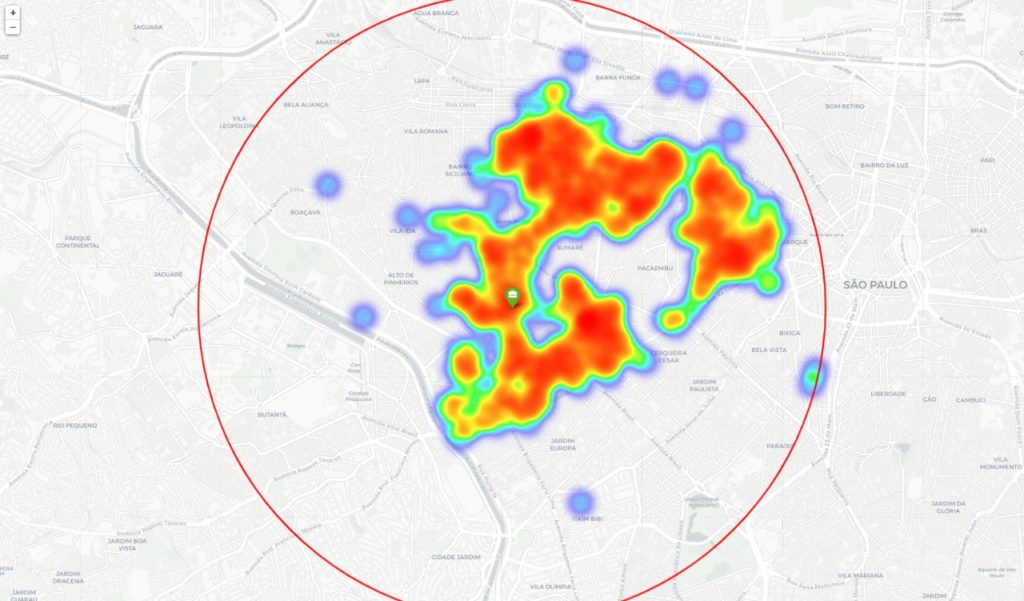
Para complementar nossa visualização, um mapa de calor foi criado para ver a distribuição pelos bairros.
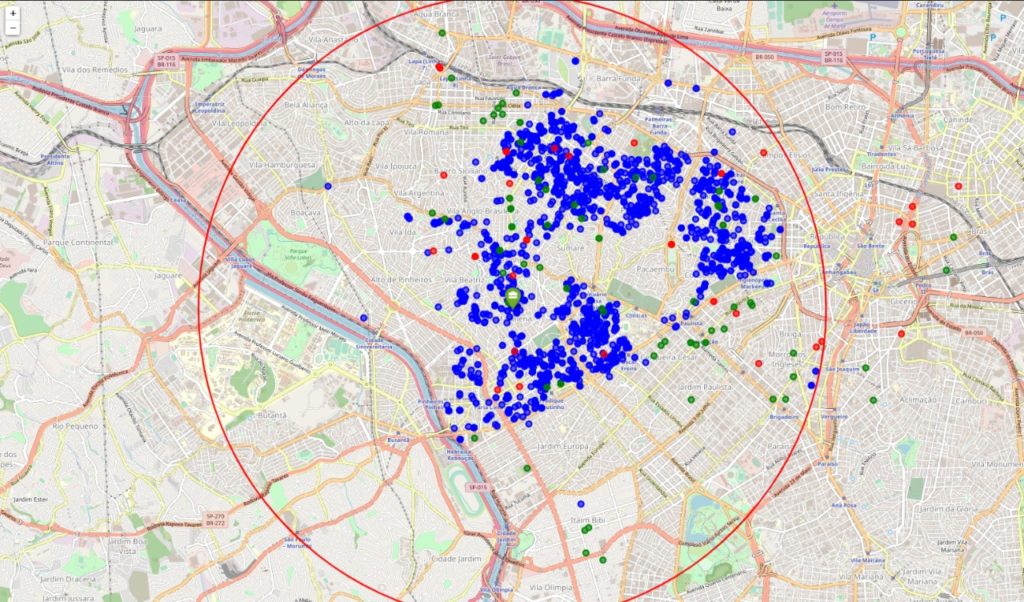
3.2 Extraindo locais específicos
Para extrair os dados de nossos locais, selecionamos cada bairro em nosso conjunto de dados de propriedades e usamos a biblioteca geocoder para extrair a localização de cada um. Em seguida, criamos uma função para acessar a API do Foursquare e retornar os 100 locais mais próximos de cada bairro. A API do Foursquare retorna o nome do local, latitude, longitude e sua categoria. Em seguida, filtramos nossos locais específicos e criamos um mapa com todos os nossos apartamentos, academias e mercados.
3.3 Agrupando dados de locais e bairros
Com a categoria dos locais, agrupamos o conjunto de dados para ver quais foram os nossos 10 locais mais comuns de cada bairro, definindo suas características sociais. Com nosso conjunto de dados de imóveis, agrupamos nos bairros para extrair suas características econômicas, como valor médio de aluguel, área privativa média, número médio de quartos, etc.

3.4 Clustering
Decidimos agrupar nossos bairros em 5 grupos utilizando o algoritmo k-means para compilar as informações em macro-grupos. Aparentemente os bairros são muito semelhantes ou não tínhamos dados suficientes para o bom desempenho do algoritmo, resultando em um único grupo com aproximadamente 64% dos resultados.
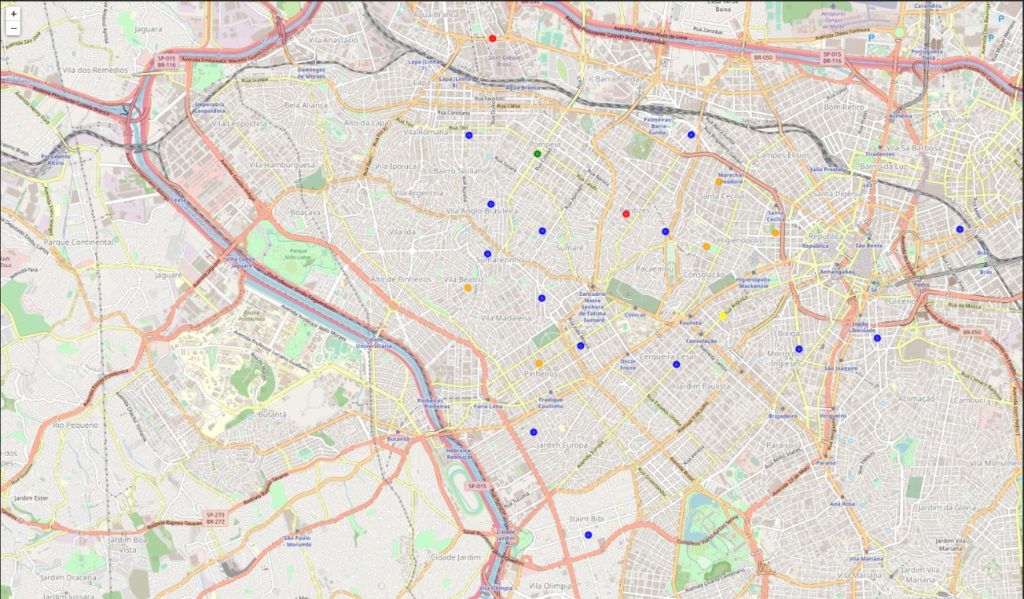
3.5 Apartamentos potenciais
Para se adequar ao nosso perfil, nossa nova casa deve estar pelo menos 1 km de uma academia e um mercado. Para isso, criamos dois conjuntos de dados com as informações de todas as academias e todos os mercados extraídos. Posteriormente, iteramos em cada apartamento e em cada local para calcular a distância entre eles e extraímos o local mais próximo de cada um deles. Com isso pudemos criar um mapa com todos os nossos apartamentos e a academia e mercado mais próximos para cada um.
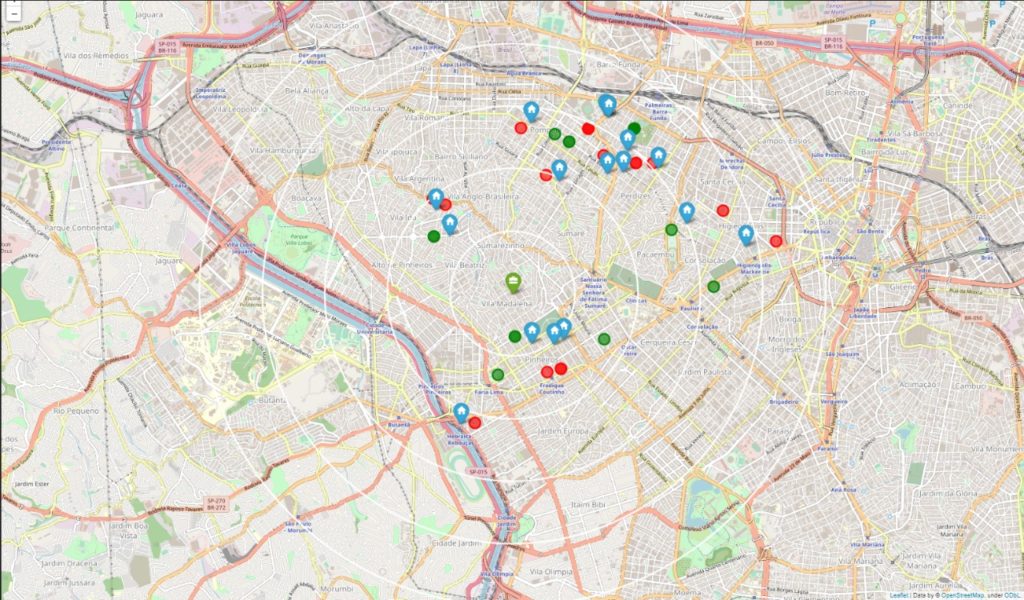
3.6 Conjuntos de dados finais
Com os dados sociais e econômicos de cada bairro, pudemos criar um único conjunto de dados com cada apartamento potencial agrupado com os dados do respectivo bairro, resultando em um único conjunto de dados com todas as informações coletadas.
4. Resultados e discussão
Nossa análise mostra que embora haja um grande número de apartamentos (~ 3.000) em nosso conjunto de dados original, apenas alguns (17) se enquadram em nosso perfil. Nosso primeiro filtro com o objetivo de obter apenas apartamentos em um raio de 5km para nosso local de trabalho não filtrou muitos imóveis (~ 100) e isso porque já havíamos filtrado os bairros para colher os dados.
O heatmap mostra que há uma clara concentração de apartamentos nos bairros que filtramos inicialmente, resultando em um pequeno viés em nossos resultados. Para os próximos projetos, poderíamos considerar colocar todos os bairros em um raio de 5 km do nosso ponto de partida.
Depois de agrupar os dados econômicos e sociais dos bairros, agrupamos os bairros em 5 grupos. Aparentemente, os bairros são muito semelhantes entre si, resultando em alta concentração em um dos grupos (~ 64% dos bairros).
Para encontrar nossos apartamentos potenciais, aplicamos os filtros finais considerados como número de quartos, distância mínima de locais específicos e valor máximo do aluguel mensal. O filtro foi muito eficaz, filtrando aproximadamente 99,4% dos resultados.
Para gerar nosso conjunto de dados final, agrupamos os dados de cada apartamento com as informações dos locais de interesse mais próximos e os dados econômicos e sociais do bairro. Isso nos proporcionou uma visão ampla das características de cada apartamento e do seu entorno.
5. Conclusão
O objetivo desse projeto era encontrar o melhor apartamento para alugar em São Paulo que se encaixasse no nosso perfil. Ao reunir dados de apartamentos em bairros próximos e extrair os dados sociais e econômicos desses bairros, geramos um conjunto de dados concentrado com os apartamentos mais promissores para se morar.
A decisão final deve ser sempre tomada com cuidado após examinar cada apartamento individualmente. O projeto ajudou a filtrar o grande número de apartamentos e agrupar os dados de cada apartamento potencial e os dados sociais e econômicos de seu respectivo bairro. Dados de qualidade de vida, criminalidade, mobilidade urbana etc. não foram levados em consideração e podem ser indicadores interessantes a serem observados em próximos projetos para melhorar a análise.
Todo o código do projeto está disponível neste repositório do github: https://github.com/arturlunardi/Coursera_Capstone